- Comment réparer l'URL soumise bloquée par robots txt?
- Comment débloquer les robots txt?
- Que signifie bloqué par robots txt?
- Mon site Web a-t-il besoin d'un fichier txt robots?
- Comment vérifier si robots txt fonctionne?
- Comment activer le txt des robots?
- Qu'est-ce que le robot txt dans le référencement?
- Est-ce que Google respecte les robots txt?
- Comment puis-je m'assurer que Google n'est pas bloqué?
- Google peut-il explorer sans robots txt?
- Comment désactiver le sous-domaine dans robots txt?
- Comment bloquer un robot d'exploration dans robots txt?
Comment réparer l'URL soumise bloquée par robots txt?
Mettez à jour vos robots.
txt en supprimant ou en modifiant la règle. Généralement, le fichier se trouve à l'adresse http://www.[votre nom de domaine].com/robots.txt cependant, ils peuvent exister n'importe où dans votre domaine. Les robots. L'outil de test txt peut vous aider à localiser votre fichier.
Comment débloquer les robots txt?
Pour empêcher les moteurs de recherche d'indexer votre site Web, procédez comme suit :
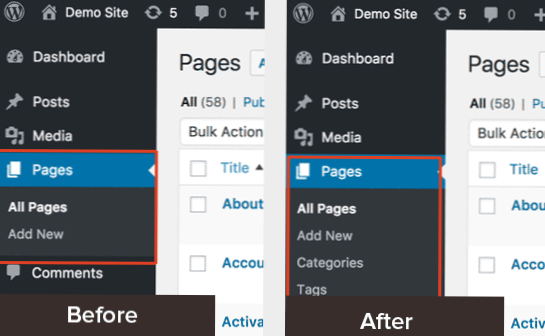
- Connectez-vous à WordPress.
- Allez dans Paramètres → Lecture.
- Faites défiler la page jusqu'à l'endroit où il est indiqué « Visibilité sur les moteurs de recherche »
- Décochez la case à côté de « Décourager les moteurs de recherche d'indexer ce site »
- Appuyez sur le bouton « Enregistrer les modifications » ci-dessous.
Que signifie bloqué par robots txt?
Si votre page Web est bloquée avec un fichier robots. txt, il peut toujours apparaître dans les résultats de recherche, mais le résultat de la recherche n'aura pas de description et ressemblera à ceci. Les fichiers image, fichiers vidéo, PDF et autres fichiers non HTML seront exclus.
Mon site Web a-t-il besoin d'un fichier txt robots?
La plupart des sites Web n'ont pas besoin de robots. fichier txt. C'est parce que Google peut généralement trouver et indexer toutes les pages importantes de votre site. Et ils n'indexeront PAS automatiquement les pages qui ne sont pas importantes ou les versions en double d'autres pages.
Comment vérifier si robots txt fonctionne?
Testez vos robots. fichier txt
- Ouvrez l'outil de testeur pour votre site et faites défiler les robots. ...
- Tapez l'URL d'une page de votre site dans la zone de texte en bas de la page.
- Sélectionnez l'agent utilisateur que vous souhaitez simuler dans la liste déroulante à droite de la zone de texte.
- Cliquez sur le bouton TEST pour tester l'accès.
Comment activer le txt des robots?
Tapez simplement votre domaine racine, puis ajoutez /robots. txt à la fin de l'URL. Par exemple, le fichier robots de Moz se trouve sur moz.com/robots.SMS.
Qu'est-ce que le robot txt dans le référencement?
Les robots. txt, également connu sous le nom de protocole ou norme d'exclusion des robots, est un fichier texte qui indique aux robots Web (le plus souvent aux moteurs de recherche) les pages de votre site à explorer. Il indique également aux robots Web quelles pages ne pas explorer.
Est-ce que Google respecte les robots txt?
Google a officiellement annoncé que GoogleBot n'obéirait plus à un Robot. txt directive relative à l'indexation. Les éditeurs s'appuyant sur les robots. txt noindex a jusqu'au 1er septembre 2019 pour la supprimer et commencer à utiliser une alternative.
Comment puis-je m'assurer que Google n'est pas bloqué?
Créer une balise méta
Voici quelques balises méta courantes que vous pouvez ajouter à vos pages HTML pour : Empêcher des articles spécifiques de votre site d'apparaître dans Google Actualités, bloquer l'accès à Googlebot-News à l'aide de la balise méta suivante : <meta name="Googlebot-News" content="noindex, nofollow">.
Google peut-il explorer sans robots txt?
le fichier txt n'existe pas. Cela signifie que les robots d'exploration supposeront généralement qu'ils peuvent explorer toutes les URL du site Web. Afin de bloquer l'exploration du site Web, les robots.
Comment désactiver le sous-domaine dans robots txt?
Oui, vous pouvez bloquer un sous-domaine entier via des robots. txt, mais vous devrez créer un fichier robots. txt et placez-le à la racine du sous-domaine, puis ajoutez le code pour ordonner aux robots de rester à l'écart du contenu de l'ensemble du sous-domaine.
Comment bloquer un robot d'exploration dans robots txt?
Si vous souhaitez empêcher le bot de Google d'explorer un dossier spécifique de votre site, vous pouvez mettre cette commande dans le fichier :
- User-agent : Googlebot. Interdire : /example-subfolder/ User-agent : Googlebot Interdire : /example-subfolder/
- Agent utilisateur : Bingbot. Interdire : /example-subfolder/blocked-page. html. ...
- User-agent : * Interdire : /